2010年に裁断機とドキュメントスキャナを買って、いわゆる「自炊」を始めてから5年が経過しました。そろそろ刃も研がなきゃいけないし、ドキュメントスキャナの買い換えも検討しなきゃいけないな、と思ったので、これを機会に今までの自炊についてまとめてみることにしました。
どのくらい自炊したのか
- 冊数: 1087冊
- 枚数: 130626枚
冊数は、ファイルサーバーに保存してあるPDFのファイル数、枚数はScansnapのユーティリティでのカウントです。1年で200冊。それ以前と比べると部屋の本はかなり減りましたね。本棚3本あったのが1本まで減りました。
裁断について
裁断機
自炊界のデファクト・スタンダードである、プラスのPK-513Lを使っています。買って5年が経過しましたが、刃の切れ味が少し鈍くなったと感じるぐらいで、その他の使い心地は全然変わりません。なお、今だと独ダーレ社の200DXというのが、さらに強化されていて良いようです。
切る時のポイント
平とじの本(背表紙が平らな本。漫画の単行本など)は、端から5mmぐらいのところで切っています。これぐらい切るとノリがほぼ取れます。結構ギリギリなので、切った後にくっついているページがあったら手で切り離す作業は必須です。ただ、これでも見開きの絵などは結構かけてしまいますが、これはしょうがないです。
中とじの本(大きなホッチキスで留めてある本。雑誌など)は、針を取り除いた後に、真ん中で切ります。うまく真ん中で切らないと、前半ページの端が後半ページに、なんてことにもなるので、慎重に行きましょう。
スキャンについて
ドキュメントスキャナ
これまた自炊界のデファクト・スタンダード(当時)である、PFUのScanSnap S1500を使っています。消耗品はメーカーの指定通り1年ごとに変えています。世の中には、パッドユニットのゴムを自力で交換する人とか、パッドユニットの互換品を売っている店もあるそうですが、私は純正品だけを使っています。枚数の上限ではなくて1年で取り替えることが多く、少しもったないなくも思っていますが。
スキャナの設定
プリセットを2つ作って、切り替えて使っています。以下に要点を示します。
- 読み取り後のアプリ「起動しない」
- 画質「スーパーファイン」
- カラーモード「グレー」or「カラー」。「自動」は使っていません。「白黒」も、図があるページだけグレーにするのも面倒くさいので、使っていません。基本的に不自由していませんが、「G.A. 芸術科アートデザインクラス」の単行本は、グレーとカラーが入り交じっているので、苦労しました(1枚の表裏で切り替わるとかある)。
- 読み取り面「両面読み取り」かつ「継続読み取りを有効」
- オプションは全て無効。
- ファイル形式はPDF。
- 圧縮率は「1」(最も圧縮が弱いモード)。
- OCRは行いません(Acrobatで行います)。
スキャンする時
紙のセットの仕方にコツがあります。
そのままセットすると、少ない枚数で簡単に紙送りが止まってしまうのですが、下の写真のように「下の紙をずらす感じで」セットすると、紙送りが止まりづらくなります(下にある紙は若いページ番号のページです)。


漫画本や雑誌だと、大抵「カラー→白黒→カラー」のように、最初がカラーで、真ん中が白黒で、最後がカラー、みたいになるので、この場合だったら紙の束を3つに分けて、「カラー設定」→「グレー設定」→「カラー設定」で読み込んで、3つのPDFファイルを作成します。あとはAcrobatで結合すれば良いです。
あと、カバーは、長尺モードでそのままスキャンし、後でGIMPで処理します(後述)。
読み取り後について
現在はAcrobat Pro DCを使っています。なぜProかというと、アクションウィザードを使いたいからです(後述)。
カバーの画像ファイル(後述)を扱うために、設定が1つ必要です。
「編集」→「環境設定」から「ページ表示」→「解像度」の「カスタム解像度」を選び、「300ピクセル/インチ」を選択します。これで、画像をPDFファイルにページとして挿入した時に、300dpiになるので、スキャンした画像を適切に扱うことができます。
本のPDFファイルにカバー画像を追加する
長尺モードでスキャンしたカバー画像を、「表紙」「表紙の見返し」「裏表紙の見返し」「裏表紙」の4つの画像に分け、本をスキャンしたPDFファイルに挿入します。作業にはGIMPを使用しています。
GIMPで、「ファイル」→「開く/インポート」から、長尺でスキャンしたカバーのPDFをインポートします。その際、「解像度」を「300ピクセル/in」にして下さい。回転が必要なら「画像」→「変形」から回転させて下さい。
また、本をスキャンしたPDFファイルを、Acrobatで開き、ページサムネールを表示した状態にして下さい。
まず、表紙部分の画像をPDFファイルの中に挿入します。GIMPで、「選択ツール」→「矩形選択」から、表紙部分の領域を選択し、「編集」→「コピー」して下さい。
選択した画像を、PDFに追加します。Acrobatのページサムネール上で右クリックし、「ページを挿入」→「クリップボード」を選択して下さい。すると、「ページを挿入」ダイアログが出てきますので、「前」「最初」(最初のページの前)を選択して下さい。すると、選択した画像が最初のページに挿入されます。もし、画像のサイズが変だったら、解像度設定を確認して下さい(前述)。
同様に「表紙の見返し」「裏表紙の見返し」「裏表紙」を、それぞれ適切な位置に挿入して下さい。
PDFファイルの扱い
カバーを挿入した状態のファイルを一旦保存します。このファイルは保存用として取っておきます。
次に、文字が多い本は、この段階でOCRを行います。OCRは、Acrobatの「ツール」→「スキャン補正」→「テキスト認識」から行えます。OCRの設定では、「出力」を「編集可能なテキストと画像」にしています。これが以前のバージョンでいう「ClearScan」になります。
最後に、OCRした/しないにかかわらず、出力されたファイルをJPEG2000で圧縮し直します。JPEGに比べて、同じ見た目(当社比)で、ファイルサイズを2分の1ぐらいにすることができます。
PDFファイルを開いた状態で、「ファイル」→「その他の形式で保存」→「最適化されたPDF」を選択します。するとこのような画面が出てくるので、パラメータを入力します。
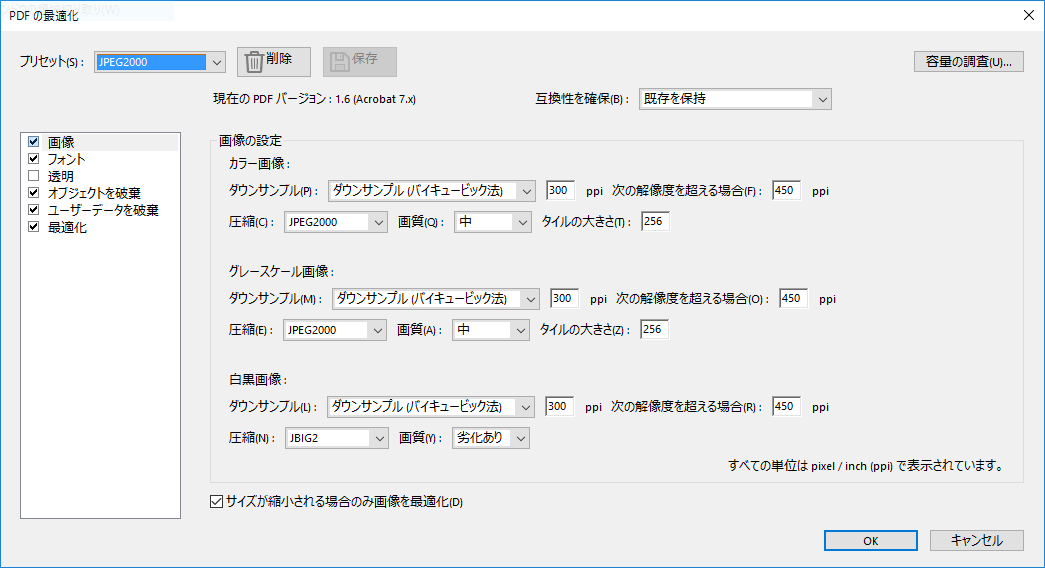
「圧縮」に「JPEG2000」を指定するのがポイントです。
なお、B5雑誌の場合、これでもファイルサイズが非常に大きくなってしまうので、泣く泣く解像度を2分の1に落としています。
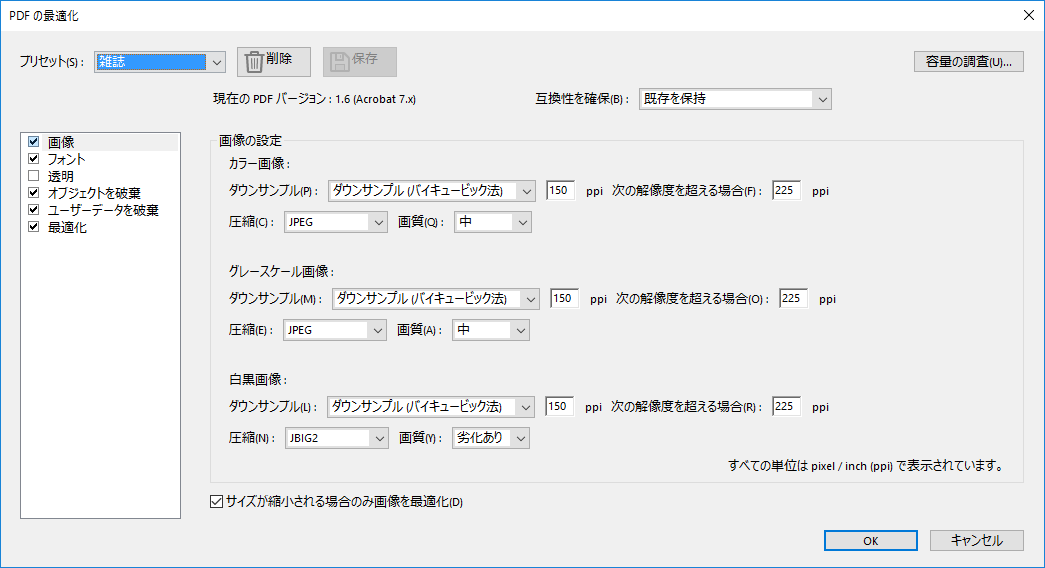
この設定だと、B5で340ページの雑誌が、85MB程度になります。
なお、この解像度のコンバートは、手動ではなくてアクションウィザードを使って複数ファイルを連続で行うことができます。寝ている間にできるので、その方が良いでしょう。
ファイルの運用
できあがったPDFファイルは、WebDAVに入れて、インターネットからダウンロードできるようにしています(もちろん、不特定多数への公開ではなく、自分のみがパスワードを知っているWebDAVです)。
読む端末はiPadやiPhoneを使い、ソフトにはi文庫S/i文庫HDを使っています。ソフト単体でWebDAVに対応しているので、使い勝手が良いです。
このようにして、物理的な本を減らしながら生活しています。